
作者:杨 阳 林鸿飞 杨 亮 任巨伟 责任编辑:网络部 信息来源:《中文信息学报》2017年第3期 发布时间:2018-03-14 浏览次数: 4805次
【摘 要】政治学研究一直是社会科学领域的热点研究方向。政治理论、比较政治、公共政策和国际政治等,这些经典的政治学研究课题吸引了大批的政治学学者。从传统政治学研究中的道德哲学和法理主义,到行为主义政治学研究中的科学方法论和定量分析,再到一些自然科学工作者开始涉足政治学领域,政治学的研究方法一直在发展与演变。该文在对传统政治学研究的方法进行简要总结的基础上,针对互联网时代,“大数据”驱动下的政治学研究,阐述了计算政治学的起源、定义及其主要的研究内容和方法,论述了目前研究的热点政治倾向性及政治观点识别、冲突观点检测、选举预测和分析可视化的研究进展。
【关键词】计算政治学;计算社会科学;大数据;研究方法;
一、引言
随着大数据时代的来临,无论是在电视、报刊、广播等传统媒体,还是在门户网站、博客、微博等网络媒体,都能看到对其大幅的报道与转载。《大数据时代》的作者维克托指出,我们正处于一个生活、工作与思维大变革的时代。在这个时代中无论是政客、商人还是学者,都会有意无意的与这些数据打交道。一条条购物记录,一段段微博留言,一趟趟航空旅行,都会化为一条条的电子数据,记录着生活的轨迹,镌刻着生命的历程。如何从这些数据中挖掘其潜藏的价值,就成为了如今学者们研究的热点。
对于大数据的定义,至今没有特别权威的解释,不同的专业领域,不同的学科背景,不同的应用场景都有着不同的阐释。“大数据”一词最早源于自然科学研究中,如天文学、生物学、计算机科学等。但如今,这个概念几乎应用到了所有人类工作、学习和生活的领域中。如图1所示,在知网中以“大数据”进行关键字检索。从2012-2013年,国内学者对于大数据的研究开始变热,文章数量呈井喷式的增长。从文章标题和所发期刊来分析,大多数是计算机科学领域对大数据的研究,其中包括对大数据的存储、并发计算,以及机器学习、文本分析等方法的论述。也有部分文章是在大数据时代下对社会科学,如管理学、社会学、经济学等研究的探讨,具体包括对大数据背景下产品评论挖掘、情感倾向性分析、企业竞争情报的研究、数据新闻报道等。

在微博、微信、人人网等社交媒体存在的今天,人们几乎每天都会在各大平台上分享自己的生活,表达一些观点和意见。而这些言论所形成的文本数据,以及附带的图片、声音等多媒体数据,对社会科学研究者来说,无疑是最宝贵的财富。如何去获取这些数据,如何从这些数据中分析管理学、社会学和其他社会科学所关心的问题,以及如何保护用户隐私,这些都是“大数据”时代下从事社会科学研究的人员所值得关注的问题,这也使得计算社会科学应运而生。
2009年,随着论文Life in the network:the coming age of computational social science在《科学》杂志上发表,计算社会科学这一崭新的学科,得到了前所未有的关注。自然科学的计算思维与人文社会科学的相容,无疑给社会科学的研究者们带来了新的思路,同时多学科的交叉,也加强了研究者们彼此间的交流与合作。
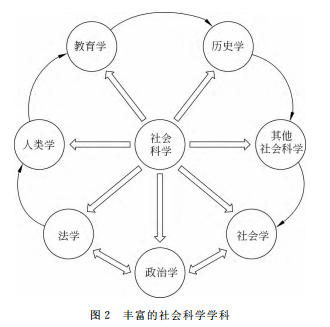
政治学是一门研究政治行为、政治体制以及政治相关领域的社会科学学科[1]。如图2所示,其与法学、社会学等其他社会科学学科有许多交叉内容,从而产生了许多边缘学科和交差学科如政治哲学、政治社会学、政治心理学等。在大数据时代,计算社会科学大力发展的背景下,政治学研究者与其他社会科学研究者一样,面临着许多机遇与挑战,诸如,如何从大量的非结构化的数据中,分析政治现象及其背后隐含的关系?如何挖掘个人及团体对某类政治事件的政治倾向?本文将对这两个问题做出回答。
二、政治学研究
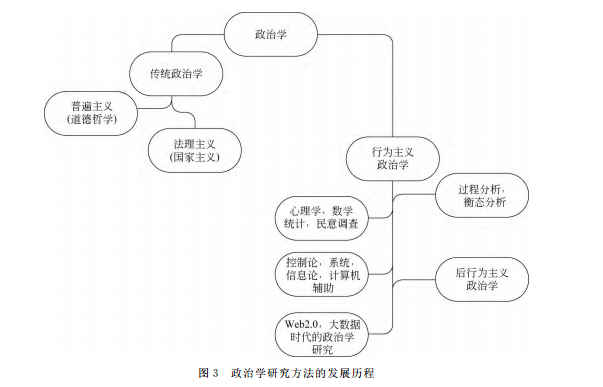
政治学研究的问题最早可以溯源到公元前,当时的政治学研究主要停留于哲学层面,最具有代表性的学者是柏拉图。其著作《理想国》将道德哲学与一般的社会问题研究融为一体,注重哲学的思辨和抽象的论证,热衷于探讨国家的抽象本质,并以实现“正义”的、“善”的国家为最高目标。
从19世纪末开始,亚里士多德认为人类对自然界进行研究,应当通过实验和逻辑分析,从而得出自己的结论。这种反传统、反迷信的主张,对后续的社会科学以及自然科学研究产生了深远的影响。他所开创的政治科学研究方法,逐渐替代以哲学思辨和抽象论证为主导地位的研究方法。从史实出发,对希腊100多个城邦进行比较和研究。在对比中,探讨国家的产生、发展及其功能。这一研究方法还接受19世纪中期孔德的实证社会学和在欧洲兴起的实证法学的影响,强调以经验为根据,着重从法律角度来研究国家、政府机关和司法机构行使权力的问题。这一学派被称为“法理主义”、“国家主义”,又因其把政治的研究偏重法律一端又被称为“法律形式主义”。
传统政治学理论的方法如历史方法、法律方法和机构方法,带有浓烈的道德和哲学色彩。政治学要成为一门“科学”,必须抛弃这种方法,对政治现象做“系统的、经验的和因果的解释”,以便使政治学能够成为一门“经验科学”[2]。
20世纪初,资本主义全面向垄断阶段过渡。随着各种非政府利益集团以及垄断组织对现实政治过程影响日益加剧,而法理主义学派对政治学的研究方法,却依旧停留在对法律体制的静态描述上。当时部分学者认为,国家的法规和政策的制定权,已经不在政府机构手中,而是掌握在非正式组织和立法机构的一些非正式委员会手里。他们认为,由于传统学派只分析政治制度而忽略了对人的分析,无法反映现实政治过程。随着阿瑟·本特利和戴维·杜鲁门《政府的过程》一书的出版,行为主义政治学流派之一的集团理论登上历史的舞台。该书把非政府机构的一些委员会和利益集团的政治行为作为政治分析的中心,通过过程分析和衡态分析方法进行分析,得出国家机构的立法和政府的决策,是由于这些机构彼此之间的相互斗争、妥协平衡的结果。
二战期间针对集团政治行为研究的方法逐渐从衡态方法转向为多学科、协同式的研究方法,重点研究“权力”理论,这也是行为主义政治学方法论的早期发展阶段。二战之后,50-60年代,自然科学的迅猛发展以及计算机的出现,为行为主义政治学方法论全面展开提供了可能。同时行为主义政治学家也竭力利用这一时期自然科学的研究新成就,全面系统地展开研究。
行为主义政治学的研究者们在理论和方法上取得了令人瞩目的成就,主要有伊斯顿的政治系统论、阿尔蒙德的结构功能主义、多伊奇的通信理论和西蒙的决策理论[3]。这些理论通过计算机辅助调查和基于统计学、数学、运筹学的定量分析,形成了严谨的基于数学公式的问题求解方法。这种定量分析的方法一直延用至今。
行为主义政治学方法,强调运用实证方法研究个体或团体的政治行为,主张政治学研究的“价值中立”,但随着行为主义政治学派的终结,逐渐被后行为主义政治学继承和改造,并得以扬弃[4]。在“价值中立”这个问题上,一些西方学者认为“价值中立”观,脱离了民主与自由,放弃了自己的社会责任,绝对的价值中立会阻碍政治学研究的发展。也正是基于这种新的认识,政治研究者们提出在政治研究的过程中,应当高度关注人的价值,不能对社会矛盾和社会危机视而不见。就此,政治学研究进入了后行为主义时代。
如图3所示,政治学研究的方法一直在发展与演变。针对互联网时代,尤其是以大数据云计算为基础,社交媒体、电子商务、移动终端等新平台,结构与非结构信息数据爆发的时代背景下,光靠传统的统计定量分析方法去挖掘这些数据背后的政治问题已经非常乏力。有必要结合计算机科学领域的自然语言处理、分布式计算、机器学习、数据挖掘等相关技术,多学科、多角度地研究与分析。
三、计算政治学概述
研究政治科学的方法通常包括正式的理论构建、叙事分析、定量分析和个案分析等[5]。其中定量分析的方法在20世纪的后半叶出现了一个研究的小高潮,并在21世纪演变成大数据的计算分析[6],且该趋势得到了社会科学研究者的不断肯定[7-8]。由于数据驱动下的计算社会科学具备收集并分析大规模数据的能力,因此,社会科学中的政治科学的研究范围逐步从个体发展到群体及社会[7]。
马萨诸塞大学阿姆赫斯特分校政治系给了计算政治科学[9]的定义:计算政治科学不但包含了对网络、传感器、通信、电子媒体或电子数据库等计算机生成数据的分析,而且使用计算形式及语言来描述和分析政治现象。主要计算研究方法包括社会网络分析、文本分析,基于主题的建模,动态关系或集群模型,数据挖掘等。
目前政治科学的主要研究领域包括:政治理论、公共政策、国际关系、比较政治。计算政治学也包括以上研究领域,但并不是简单地使用计算机进行计算,而是采用计算机科学和信息科学的技术手段分析研究政治科学。计算政治学同样不同于基于统计的政治科学。由于基于统计方法只能对少量的数据进行处理和分析,其分析方法的精确性依赖于采样的随机性,如果采样过程中存在任何偏见,分析结果就会相去甚远。这就是为什么在大数据背景下,科学家们提倡利用所有的数据,而不再仅仅依靠一小部分抽样数据的原因[10]。
在计算政治学中,文本分析通常指计算机自动内容分析或标注,主要涉及词分析[11-12]、分类聚类[13]、情感分析[14]、主题模型[15]等。政治科学和其他社会科学类似,主要研究人类的生存、竞争、合作、妥协以及社会中的交互,从而计算政治学也少不了对社交网络的分析,其中主要利用图论技术来分析并反映上所述各种关系。
目前,国外有很多学者和组织已经展开了计算政治学的研究,主要涉及的方面包括在线政治博客挖掘[16]、人与人之间的社网分析(包括传统的议会分析[17]、支持总统提名的网络分析[18])、组与组间的社网分析(例如党派,兴趣组等[19])、互联网对现实世界的影响及如何在互联网上改进政治等[20]。Hindman等人发现了政治信息在互联网上也可以被高度地关注,并且有一些链接会被多次引用[21],如一些关于某些政策的网站。在他的工作的基础上,很多政治学家在电子政府文件上开展了大量的研究,如博弈论、数理逻辑等被视为计算机科学的子领域,也被很好地应用到如选举投票等方面[22]。还有一些学者利用云计算的特性探讨了政治问题的产生[23]。
四、计算政治学研究的主要问题
(一)政治倾向性及政治观点识别
对于某类政治事件,不同个人、不同群体、不同阶层都有着不同的观点及看法。如何从微博、博客等这些社交媒体的数据中,判断个人的政治倾向,进而分析不同群体、不同阶层的政治主张,如选民支持率与地域以及阶层的关系、个人政治信息的刻画等,都成为了国外学者主要研究的内容。
Marchetti-Bowick[24]从微博中挖掘公众的当前情绪,进行政治预测,提出了一种Distant Superision方法来提高主题识别和情感分析的性能,并在一个关于奥巴马演讲的微博数据集上进行了验证。Balasubramanyan从政治博客帖子中预测评论的极性,对于一个特定政治群体的成员,预测其对不同新闻消息的情感倾向性以及根据帖子的内容预测评论的情感倾向性[25]。也有学者对Twitter用户所发的内容进行潜在语义分析,从用户大量的Twitter数据中分析用户的政治倾向[26]。Abbott分别使用了meta-post特征、上下文特征、依存特征和基于词的特征、问答特征等多种特征来识别在线讨论专栏中的政治观点。结果表明,使用上下文特征和问答特征能取得68%的准确率[27]。
在政治世界中,有很多人乐于不断跟踪观察某个候选人,一些人甚至建议直接分析Twitter数据中对不同候选人的情感倾向性可以比传统的投票结果更好,可见倾向性分析成为了计算政治学研究中的一个重要组成部分。值得一提的是Philip Resnik,他没有重点研究文本数据中情感倾向性的正反,而是将主要精力放在研究如何使用语言来对某一事件产生积极或者消极的影响,例如发现故意制造某些争论的社会现象[28]等。
(二)冲突观点检测
医疗、教育、住房等这些关乎民生的话题,在社交媒体中经常会受到关注。对于某项政策的颁布或修改,不同的个人或者团体都有着各自的观点与看法,不同的观点在表达的同时,会有不同的响应。有些观点切中要害与部分人看法吻合,会被大量的转发和支持;某些观点违背了部分人的意愿,也会被大量的转发与质疑。对于某类政治事件,往往会有多方观点共存,这些观点有的互相补充,有的却大相径庭。针对这类问题的研究,包括冲突观点的识别、检测与分析,也成为了计算政治学主要研究的内容。
在美国,政治论述越来越两极化。两极化导致对同样的新闻事件,不同的政治团体有不同的反应。针对这种不同反应的研究,可以分析团体的性质、政治主张等。对此许多学者做了相关的研究,Balasubramanyan提出了一个多目标、半监督潜变量模型———MCR-LDA[29]来模拟这个过程,通过分析不同政治组织的政治博客和评论来预测新闻话题引起的两极化程度。Fang定义和提出了一种挖掘对比观点的模型,对于一个给定的主题和一系列多观点评论,首先逐一分析各个观点,然后量化各个观点的不同,从而挖掘政治文本中的对立观点[30]。
针对政治观点的冲突检测,研究者所采用的语料大多来自于微博、政论博客、社区论坛等。这些自由的言论几乎都是非结构化数据,用以往的研究方式和传统方法很难去定量的分析。于是诸多研究者们开始采用主题模型、文本分类聚类这些计算机文本分析的方法来解决相关问题。
(三)选举预测
淘宝可以推荐人们需要的商品,微博可以知道人们的兴趣、爱好,腾讯QQ可以猜出人们认识的人是谁,并准确的将其分类。试想,如果人们拥有大量的电子病例档案,是否可以提前预测疾病,以及推荐合适的治疗措施?所以说大数据的核心就是预测[10]。通过以往的数据来预测即将发生的事情,这是多么美妙的一件事情。在计算政治学的研究中,选举预测也毫无例外的成为了其研究的核心。
选举预测多指通过分析社交媒体中关于大选的文本内容,量化情感变量,刻画情感走势,进而预测大选结果。PLEAD指出在2012年的美国大选中来自互联网及移动终端的数据对选举结果及预测方面起到了重要的作用。此外,也有一些其他方面的预测研究,如预测某些事件对于股票走势的影响,预测哪些政论帖子会受到较高的关注,哪些会得到更多的评论[31-32],通过Twitter进行实时事件检测[33],社会事件扩散的提前预警[34]等。
针对选举的预测,国外有大量的学者从事相关的研究,并取得了一定的研究成果[35-37]。2012年美国总统大选时,Nate Silver计算出竞选双方并非处于旗鼓相当的局面,成功预测奥巴马将有90.9%机会获得大多数选票,最后也成功预测了美国50个州的投票结果。事实上,2008年的总统大选他也预测对了最终结果,美国50个州的投票结果他预测对了49个,并于2008年大选之后出版《信号与杂音:预测学的艺术与科学》一书。同样做相关研究的斯坦福大学教授Simon Jackman开发了以贝叶斯统计理论为基础的可用于计算政治学领域的R语言工具包。但并非所有的学者都支持和认同这种选举预测,Daniel Gayo-Avello[38]认为大选预测不但有趣,而且很难!但是大多数的研究者倾向于表明正面的结果,却不提供有效可再现的方法。Twitter预测大选的能力被过分夸大,许多研究难题依然存在。同时他还指出在利用Twitter数据预测大选时存在很多缺陷,如并没有一个有效的Baseline,预测都是基于假设所有的Twitter数据都是有价值的等相关问题。
类似于互联网改变了我们的生活习惯,大数据也将给政治学研究带来新的方向。各方的争论,不同思想的碰撞是必不可少的。但无论结果好坏,这将是一场思维的变革。
(四)可视化研究
可视化是利用计算机图形和图像处理技术,将数据转换成图形或图像在屏幕上显示出来,并进行交互处理的理论、方法和技术。它涉及计算机图形学、图像处理、计算机视觉、计算机辅助设计等多个领域[39]。
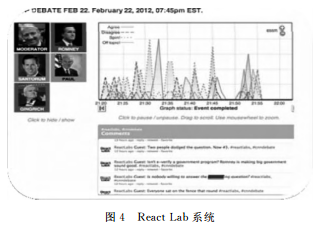
政治学研究中的可视化,旨在帮助人们更加直观地理解数据,分析数据中的规律,总结政治现象。Philip Resnik在对实时投票的研究中,利用Analyzing Twitter工具,开发了React Lab系统,该系统可以观测在线政治争论。当事件发生时,用户可通过手机等移动终端实时地讨论事件,生成动态的反应,如图4所示。
也有学者通过数据挖掘分析出紧急冲突并对其进行可视化[40],用户可通过系统进行反馈交互,获得更好的效果。目前对于政治学领域的可视化研究,学者们并不需要研究可视化底层的知识,大多数都是根据自身研究的情况,依托于已经成型的可视化系统,更加友好、人性化、交互式地展现自己的研究成果。
五、机遇与挑战
目前,大数据思维已渗入并影响着诸多研究领域,多数学者通常采用4V(Volume、Variety、Velocity、Value),即数据体量大、数据类型多、处理速度快和价值密度低,来概括大数据的特征,并以此为基础在各自领域开展相应的研究工作。然而在社会科学的诸多领域中,受限于数据的规模或技术手段,许多研究工作仍步履维艰,其存在的共性难题主要为以下两点:一方面是面对海量数据,缺乏高效的处理方式;另一方面则是数据不足或缺失时,收集领域相关数据代价巨大或无法获取必要的数据资源。
大数据时代下的海量数据资源,再次点燃了社会科学研究者们的研究热情,让他们看到了收集和处理相关信息的希望。面对多元异构的数据源,尤其是社交媒体、网络博客、垂直型论坛和问答社区的出现,使得用户可以更加自由地在这些平台上表达自己的观点,而这些观点也更加贴近民众的诉求。通过主动挖掘社交媒体等数据源中隐含的知识及模式,可以更为全面、实时、便捷地了解用户的政治倾向等信息,相比于以往的问卷调查等被动收集数据的方式,前者无疑给政治学研究者们带来了更广阔的研究空间,且诸多的机遇也蕴含其中。
与此同时,海量的数据标签及连通的数据网络(如地理位置、用户自然信息、偏好、人际圈等),也极大地丰富了政治学研究的内容,拓展了他们的研究视野。分布式存储及并行计算能力的不断提高,也降低了大数据的计算和分析大数据的成本,成为解剖大数据的一大利器。情感分析、文本挖掘、自然语言处理、机器学习以及信息检索等[41-42]方法的不断发展,更是为其提供了一套完整的收集、整理、分析、整合知识的方法体系,点亮了计算政治学研究的前路。
面对指数式增长的数据,研究者对处理和分析数据的能力提出了更高的要求。如何合理且高效地运用如自然语言处理、数据挖掘以及机器学习等在内的相关技术?如何将思辨分析的模式与这些技术更好地融合,是政治学研究者必须要面对的挑战。同时,日常生活中密不可分的智能移动终端,五花八门的社交应用,也使得大数据的分析成为了一把“双刃剑”,窃密事件的层出不穷,绝对的隐私与我们渐行渐远。因此,如何在大数据时代的研究中保护个人隐私,并规范相应的制度,引入必要的道德标准,也是政治学研究者们必须要解答的难题。综上所述,大数据时代下的计算政治学研究路途虽坎坷,但前途仍光明。
六、总结
在计算政治学的研究中总是离不开对信息的分析和处理。信息一般分为两类:一类是个人信息,另一类是事件信息。个人信息不但包括了个体的自然属性(名称、性别、出生日期、职务、特长、爱好等),也包括了个体的社会关系(关系人、关系类型、称呼、关系强度),通过这些数据构建的数据画像,能够反映人作为一个独立个体和社会成员的全面特征。从个人信息出发,进一步探究人与人的各种关系链条,并逐步扩展成为关系网络,发现特殊群体及奇异个体等重要信息,进而实现从点到面地挖掘不同组织、团体、党派之间的竞争与合作。
事件信息是另一类研究重点,主要包括各类的政治话题、政治活动等。这类信息在社交网络的传播状态大相径庭,有的经久不衰,时常见到,如国际冲突、恐怖主义等;有的却如霎那烟花,昙花一现,但仍迸发出巨大的能量,激起社会情绪的一时波澜。对于这类信息的传播过程,我们不但应考量影响信息本身传播的因素,也应计算并挖掘出哪些个人、团体或党派在传播过程中起到了至关重要的作用。
在大数据时代,对于政治学的研究应该是多维度的,和诸多社会科学一样,其也会发生潜在的变化并与时俱进地发展。为促进国内政治学研究方法的进一步深入并实现与大数据时代的接轨,本文在对传统政治学研究方法进行简要综述的基础上,重点介绍了近年来国外学者对于计算政治学领域的研究,为广大的政治学研究者提供借鉴与参照,希望对政治学研究,尤其是计算政治学方面工作的开展有所帮助。
参考文献:
[1]杨光斌.政治学导论[M].北京:中国人民大学出版社,2011.
[2]王沪宁.西方政治学行为主义学派述评[J].复旦学报(社会科学版),1985,(2):93-98.
[3]谢宗范.西方政治学研究方法的逻辑发展[J].上海社会科学院学术季刊,1988,(4):104-106.
[4]叶娟丽.行为主义政治学方法论研究论纲[J].武汉大学学报(社会科学版),2002,55(5):594-599.
[5]Political science[EB/OL].http://en.wikipedia.org/wiki/Political science.2014.
[6]Watts D J.A twenty-first century science[J].Nature,2007,445(7127):489-489.
[7]Lazer D,Pentland A S,Adamic L,et al.Life in the network:the coming age of computational social science[J].Science(New York,NY),2009,323(5915):721.
[8]Butz W P,Torrey B B.Some frontiers in social science[J].Science,2006,312(5782):1898-1900.
[9]Leilei Zhu.Computational Political Science Literature Survey[EB/OL].http://www.personal.psu.edu/luz113/,2010.
[10]维克托·迈尔-舍恩伯格,肯尼斯·库克耶.盛杨燕,周涛,译.大数据时代[M].杭州:浙江人民出版社,2013.
[11]Slapin J B,Proksch S O.A scaling model for estimating time-series party positions from texts[J].American Journal of Political Science,2008,52(3):705-722.
[12]Monroe B L,Colaresi M P,Quinn K M.Fightin′words:Lexical feature selection and evaluation for identifying the content of political conflict[J].Political Analysis,2008,16(4):372-403.
[13]Purpura S,Hillard D.Automated classification of congressional legislation[C]//Proceedings of the 2006international conference on Digital government research.Digital Government Society of North America,2006:219-225.
[14]Thomas M,Pang B,Lee L.Get out the vote:Determining support or opposition from Congressional floor-debate transcripts[C]//Proceedings of the 2006conference on empirical methods in natural language processing.Association for Computational Linguistics,2006:327-335.
[15]Quinn K M,Monroe B L,Colaresi M,et al.How to analyze political attention with minimal assumptions and costs[J].American Journal of Political Science,2010,54(1):209-228.
[16]Adamic L A,Glance N.The political blogosphere and the 2004 US election:divided they blog[C]//Proceedings of the 3rd international workshop on Link discovery.ACM,2005:36-43.
[17]Fowler J H.Connecting the Congress:A study of cosponsorship networks[J].Political Analysis,2006,14(4):456-487.
[18]Hans Noel.“A Social Networks Analysis of Internal Party Cleavages in Presidential Nominations,1972-2008”.[EB]/[OL].2009.Available at:http://works.bepress.com/hans_noel/9/.
[19]Koger G,Masket S,Noel H.Partisan webs:information exchange and party networks[J].British Journal of Political Science,2009,39(03):633-653.
[20]Han J,Kim Y.Obama Tweeting and Twitted:sotomayors nomination and health care reform[C]//Processings of the APSA 2009Toronto Meeting Paper.2009.
[21]Hindman M,Tsioutsiouliklis K,Johnson J A.Googlearchy:how a few heavily-linked sites dominate politics on the web[C]//Processings of the annual meeting of the Midwest Political Science Association.2003,(4):1-33.
[22]Jakulin A,Buntine W,et al.Analyzing the US Senate in 2003:Similarities,networks,clusters and blocs[J].Political Analysis 2009,17(3):291-310.
[23]Jaeger P T,Lin J,Grimes J M.Cloud computing and information policy:Computing in a policy cloud?[J].Journal of Information Technology&;Politics,2008,5(3):269-283.
[24]Marchett Bowick M,Chambers N.Learning for microblogs with distant supervision:Political forecasting with twitter[C]//Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics.Association for Computational Linguistics,2012:603-612.
[25]Balasubramanyan R,Cohen W W,Pierce D,et al.What pushes their buttons?:predicting comment polarity from the content of political blog posts[C]//Proceedings of the Workshop on Languages in Social Media.Association for Computational Linguistics,2011:12-19.
[26]Conover M D,Gon9alves B,Ratkiewicz J,et al.Predicting the political alignment of twitter users[C]//Processings of the ieee third international conference on and 2011ieee third international conference on social computing(socialcom).IEEE,2011:192-199.
[27]Abbott R,Walker M,Anand P,et al.How can you say such things?!?:Recognizing disagreement in informal political argument[C]//Proceedings of the Workshop on Languages in Social Media.Association for Computational Linguistics,2011:2-11.
[28]Greene S,Resnik P.More than Words:Syntactic Packaging and Implicit Sentiment[C]//Proceedings of Human Language Technologies:Conference of the North American Chapter of the Association of Computational Linguistics,Boulder,Colorado,USA.DBLP,2009:503-511.
[29]Balasubramanyan R,Cohen W W,Pierce D,et al.Modeling polarizing topics:when do different political communities respond differently to the same news?[C]//Processings of the ICWSM.2012.
[30]Fang Y,Si L,Somasundaram N,et al.Mining contrastive opinions on political texts using cross-perspective topic model[C]//Proceedings of the fifth ACM international conference on Web search and data mining.ACM,2012:63-72.
[31]Yano T,Smith N A.Whats Worthy of Comment?Content and Comment Volume in Political Blogs[C]//Processings of the ICWSM.2010.
[32]Yano T,Cohen W W,Smith N A.Predicting response to political blog posts with topic models[C]//Proceedings of Human Language Technologies:The2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics.Association for Computational Linguistics,2009:477-485.
[33]Sakaki T,Okazaki M,Matsuo Y.Earthquake shakes Twitter users:real-time event detection by social sensors[C]//Proceedings of the 19th international conference on World wide web.ACM,2010:851-860.
[34]Colbaugh R,Glass K.Early warning analysis for social diffusion events[J].Security Informatics,2012,1(1):1-26.
[35]Bermingham A,Smeaton A F.On Using Twitter to Monitor Political Sentiment and Predict Election Results[C]//Proceedings of the Workshop on Sentiment Analysis where AI meets Psychology(SAAIP).IJCNLP,2011.
[36]Tumasjan A,Sprenger T O,Sandner P G,et al.Predicting Elections with Twitter:What 140Characters Reveal about Political Sentiment[J].ICWSM,2010,10:178-185.
[37]Skoric M,Poor N,Achananuparp P,et al.Tweets and votes:A study of the 2011singapore general election[C]//Processings of the 2012 45th Hawaii International Conference on.IEEE,2012:2583-2591.
[38]Gayo-Avello D.“I Wanted to Predict Elections with Twitter and all I got was this Lousy Paper”——A Balanced Survey on Election Prediction using Twitter Data[J].arXiv preprint arXiv:1204.6441,2012.
[39]可视化.[EB]/[OL].http://baike.baidu.com/view/69230.htm.2014
[40]Johansson F,Brynielsson J,Horling P,et al.Detecting emergent conflicts through web mining and visualization[C]//Processings of the Intelligence and Security Informatics Conference(EISIC),2011European.IEEE,2011:346-353.
[41]杨亮,林鸿飞,基于情感分布的微博热点事件发现,中文信息学报[J],2012,26(1):84-90.
[42]魏现辉,张绍武,杨亮,林鸿飞.基于加权SimRank的跨领域文本倾向性分析[J].模式识别与人工智能,2013,26(11):1004-1009.
注释:
[1]《政府的过程》(1908)一书被认为是团体理论的代表著作。
[2]行为主义是指20世纪40年代末50年代初在美国崛起并逐渐占居主流的一个政治学流派,称之为行为主义政治学派,或行为主义学派,它以拉斯韦尔、阿尔蒙德、达尔、尤劳等著名政治学家为代表。
[3]“价值中立”,是相对于价值判断而言的。由于价值判断是审美偏好和情感偏好的表达,缺乏客观性,所以“价值中立”这一原则的主旨在于要求科学家在从事的研究中应当保持客观态度,不受个人主观好恶或价值观念的影响。
[4]Philip Resnik认为计算政治学的兴起得益于计算社会科学,其主要在计算政治学领域中研究以下三个方面:实时投票,计算模型在分析政治对话中的作用或效果,倾向性分析。
[5]PLEAD是CIKM一个专门针对政治学的Workshop,其核心是分析在大选中互联网上的大数据扮演着怎么样的角色。该Workshop的宗旨是将涉及社会网络分析的各个研究者集中在一起,解决计算社会科学和计算政治学中的问题。
[6]Simon Jackman现为斯坦福大学PSCL(Political Science Computational Laboratory)主任。主页地址http://jackman.stanford.edu/pscl/.
 |
你是第81679765位访客
Copyright 华中师范大学中国农村研究院 鄂ICP备12007439号-2 Mail:newccrs@126.com Tel:027-67865189 Fax:027-67865189 本网站为纯公益性学术网站,无任何商业目的.因部分文章来源于网络,如有侵权请来邮或来电告知,本站将立即改正 |
 |

